These are the notes I took while reading the book “Clean Code: A Handbook of Agile Software Craftsmanship” (Robert C. Martin)]1, that are supposed to summarize the main concepts presented in the book.
The book has a mission to “improve the state of software craftmanship”. A lot of reasoning and moralizing at the beginning, I’ll skip that (still it is really worth reading!) :) What I liked the most:
We want to use the popular paperback model whereby the author is responsible for making himself clear and not the academic model where it is the scholar’s job to dig the meaning out of the paper.
Just gonna mention that all the advice comes not from guesses but experience (as the author claims).
Table of contents
- Dictionary
- 1. Meaningful Names
- 2. Functions
- 3. Comments
- 4. Formatting
- 5. Objects and Data Structures
- 6. Error Handling
- 7. Boundaries
- 8. Unit Tests
- 9. Classes
- 10. Systems
- 11. Emergence
- 12. Concurrency
- 13. Successive Refinement
- 14. JUnit Internals
- 15. Refactoring SerialDate
- 16. Smells and Heuristics
- 17. Appendix A: Concurrency II
- 18. Appendix B: org.jfree.date.SerialDate
Dictionary
Because I hate getting stuck on abbreviations:
- OCP - Open-Closed Principle - Classes should be open for extension but closed for modification.
- SRP - Single Responsibility Principle - A class or module should have one, and only one, reason to change.
- DIP - Dependency Inversion Principle - Classes should depend upon abstractions, not on concrete details.
[note that I skipped the first chapter, so the numbering of chapters is shifted by -1, comparing to the order in the book]
1. Meaningful Names
Variable name should say what is being measured and the unit of measurement, e.g. int elapsedTimeInDays instead of int i.
It is always useful to add the context to the variable names, e.g. gameBoard instead of theList. Also the whole class is a context to their variables/methods.
It is sometimes a good idea to extract even one-line-if-condition to a separate method, as one can give this method a more descriptive name.
It is important to keep in mind the keywords specific to different areas of IT, and avoid using them when we mean them in a different context. E.g. do not call accountList something which is not a list.
Do not use names that differ only sligthly, for example XYZControllerForEfficientHandlingOfStrings and XYZControllerForEfficientStorageOfStrings.
Do not use lowercase L together with uppercase O, as this will look like number 10. Just don’t be confusing when you don’t have to.
Avoid using noise words, like a, an, the, info, data,… to “make up” a new, non-conflicting name. For example would you be able to guess the difference between ProductInfo and ProductData?
Make your names pronouncable, so that you can later discuss the code without sounding like an idiot.
Make your variable names be easy to find via a text search - makes your life easier.
Better add suffixes to interface implementations than prefixes to the interface name. No one needs to know that e.g. ShapeFactory is an interface, it’s less ugly to name its implementation ShapeFactoryImpl.
Class names should have a noun in the name.
It is better to have factory methods and private constructors, than a big amount of overloaded constructors - because the factory methods can have descriptive names.
Don’t try to be funny when choosing names (someone may not understand).
Use consistent lexicon, e.g. get, fetch, retrieve - decide on one word to use per project, not per developer. Or same with manager vs controller vs driver.
BUT be aware to use one word only when semantics are same - for example adding two strings together is not same as adding an element to a list. Then you have to use a different name.
Problem domain (e.g. customer, account) vs solution domain (e.g. visitor, queue) terms - first try to use solution domain, then problem domain. The more code has to do with the solution domain problems, the more solution domain vocabulary it should use, and vice versa. It is important to know the difference.
Prefixing everything with same prefix may not be a good idea - as it makes it harder to use code completion. Why to work against your tools? Add no more context to the name than neccessary.
Don’t be afraid of renaming.
2. Functions
Should be smaller than small. Best 3-4 lines. Max 1-2 indent levels (e.g. if).
Each function should do only one thing. “One thing” is when you cannot split it to steps anymore.
Mixing levels of abstraction within one function is always confusing, e.g. getHtml() next to .append("\n").
The code should be read like a top-down narrative. Place the extracted function right below the function that is calling it.
Sometimes it’s worth to use polymorphism rather than a switch. Using switch often breaks the SRP (more than one reason to change) and OCP (must change whenver new types are added), and sometimes even causes duplicating the same switch costructions in several functions. Instead create classes for each switch case, and bury the switch itself deep in an Abstract Factory.
Max number of function input arguments is 2-3, best 0. They increase testing complexity. Make the function harder to understand.
Using 2 arguments is only justified for example in situations like new Point(0,0), because a point has 2 ordered coordinates. If there is no natural cohesion or ordering between arguments they should not be both input arguments of a function. E.g. the .assertEquals(expected, actual) is confusing, isn’t it. And .assertEquals(message, expected, actual) is even more confusing - how many times you had to check the signature first?
Often if a function takes many arguments it’s a sign that they should be wrapped into a class on their own.
Anything that forces you to look up a function signature is a cognitive break and should be avoided.
Avoid using flag arguments. Boolean passed into a fuction means the fuction does more than one thing! Should be split into two functions then.
Have no side effects in a function - they are evil. They may introduce temporal coupling (temporal - related to time), e.g. by hiddenly calling initialize().
Try not to use input arguments as output. Better use report.addFooter() than .addFooter(report) - that is more OO style.
Apply Command Query Separation - a function either does something or answers a question, not both. E.g. boolean setName(name) is bad, as it requires guessing what the returned value means. This should be separated into two functions.
It’s a good practice to extract the bodies of try-catch blocks into separate methods - to separate the logic from error handling. Error handling is already a one thing.
Start with writing any fuction and then refactor it, long. It’s not the goal to have them neat and nice from the start.
3. Comments
Don’t comment on bad code - rewrite it.
Comments are evil. The goal of comments is to compensate for our failure or to help express ourselves better. They are always sign of failure.
Comments get outdated as there is no good way of maintaining them. People move the code but forget the comment. People change the code but forget the comment, or no longer remember what it was supposed to mean.
They are reasonable only sometimes (express rationale behind choosing a certain approach, or to stress out some important detail in the implementation), but in general try to minimize using them.
Of course it’s different with Javadocs, Javadocs are useful, but keep them accurate. Misleading comment is worse than no comment.
If you write a comment, write about what is just next to it, not about the whole system around. Only about what the function has control over. Otherwise it will soon become outdated, and therefore misleading.
No point in writing sth like /* Returns the name. */ getName().
Using HTML in comments makes them harder to be read in IDE - so where they are read the most.
4. Formatting
Code formatting is important because it is part of communication.
It also makes the reader trust the code more.
Vertical size of a file should be typically 200 lines, with upper limit of 500 (but this is just a rough number, based on a number of open source projects; the author phrases it way more dyplomatically :P).
Newspaper metaphor - code should read like a newspaper article. First the title, then the introduction, only later the details. Name should be simple but explanatory. The article should be short enough to make it attractive to read.
It’s a good idea to put a blank line between groups of lines that represent single thought. And lines referring to single concept should be kept dense.
Keep related pieces close to each other - e.g. functions one after another, in one file. That’s why protected variables should be avoided.
Declare local variables on the top of each function (except when it’s just a loop counter, or sth similar).
Instance variables and constants shoud also be at the top of the class, even if a constant is used only in one place later - as at the top it is more visible.
Keep lines short, less than 80-120 characters. Even if your screen can fit more.
Surround = assignments with whitespaces, to accentuate them.
(some other obvious whitespace usages and antiusages)
Keep indentation. Even for one line ifs, one line whiles - expand them into multiline and add indent. Dont do while();, in one line (notice the semicolon), this is evil.
Each developer should follow common team rules, even if some of them don’t like some of them.
5. Objects and Data Structures
Don’t automatically add getters and setters to each private variable. Why would we have private variables at all then?
For example a Point - can be defined by [x,y] (carthesian coordinates) or by [r,theta] (polar coordinates). If we don’t add separate setters for x, y, r, t, but rather a setter for x, y and another setter for r, t - we enforce an access policy. And even despite having separate getters for each of x, y, r, t, we still do not expose the internal implementation.
Getters and setters are part of the interface using which the object communicates with the world. Think it through.
Object vs data structure - data structure only exposes it’s data, and object exposes functions that operate on its data. Do not mix them in one class! Do not create hybrids.
OO code makes it easier to add new classes (add new objects), and procedural code makes it easier to add new functions (add new behaviour). Always choose the style appropriate to the task at hand. Everything does not have to be an object.
An example of a procedural code is the following: we have a class Geometry and different Shape subclasses. In Geometry class there is a number of methods that operate on a Shape, in each there is switch to check which subclass of Shape are we dealing with. If we add a new shape type, we need to make changes in every method in Geometry class. If we add a new operation type, we need to only add the new function to Geometry class.
Instead, we could have each subclass of Shape have their own set of those methods - that would be exactly the OO style.
The Law of Demeter - a module should not know about the innards of the objects it manipulates. A function can call operations on elements of an object where it is declared, but not on the objects returned by those operations.
-
That is why the
ctxt.getOptions().getScratchDir().getAbsolutePath()is a candidate of breaking that law. BUT not if the subsequent classes are data structures not objects. -
And, if they are objects, there should not be “getSth” functions on them, but “doSth” functions. If we need to get sth, let’s think about what we need it for, and move that logic into that class, under a “doSth” function.
Active Records are DTOs with extra methods like save() and find(), e.g. for using with database. Treat them as data structures and don’t add more logic.
6. Error Handling
Write try-catch-finally blocks first - they define the scope, “transaction”.
Keep error handling separate from the business logic.
Unchecked exceptions are now fine. In the past they were bad practice, now they are not. It’s neccessity. Encouraging checked exceptions in Java was a mistake, as they violate OCP principle. Only use them if you write a critical library and need to force the user to catch an exception.
Classifying yor exceptions - should be done according to how they will be caught. Use different classes for your exceptions only if there are times you want catch one exception and let go the other.
Special case pattern (by Fowler) - when you feel like you want to steer your logic using exceptions - return a special, “exceptional” object instead of throwing an exception, and let the further code treat it as if is was a valid response - without knowing that it is a special case object. Sometimes this pays off.
Don’t return null. This forces you to write a lot of null checks, and of course one day you will forget one.
Don’t pass null (like calculator.xProjection(null, new Point(12, 13));).
7. Boundaries
Sometimes it’s a good idea to encapsulate Map into own object, so that the user does not see the generics. Don’t pass Maps or other boundary interfaces (i.e. coming from 3rd party general use library) around your system. They should not be part of your public API.
Learning tests - if you learn a 3rd party library, write tests that reflect your understanding. Will be helpful for others to understand and will immediately detect backward incompatibility when updating to newer version.
Boundary tests - similar to the above, but focus only on the parts used by our software.
When you want to integrate sth that is not yet implemented - feel free to write the interface yourself, and later just add an adapter.
What happens at boundaries is change. Minimize the number of touch points with 3rd party libraries.
8. Unit Tests
(Some well known rules about TDD)
Use same quality standards for tests as for production code! Otherwise maintenance will become pain in the head. No “quick and dirty” tests! Dirty tests are worse than no tests. Below an illustration of a real life story (the illustration is my own interpretation):
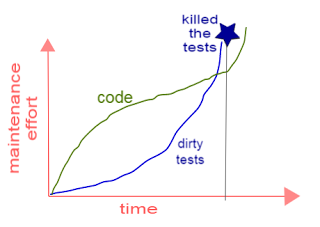
Tests keep the production code flexible.
Readability in tests is even more important than it is in production code. So refactor, remove code duplication, choose descriptive names. Make it clear where the “setup”, “run” and “assert” part is. Design the tests for reading.
Even write a set of utility methods only for your tests, that will use domain language, and provide a testing API to your system.
Keep on refactoring tests, just like you do with the production code.
Test one concept per test. A test should have only one reason to fail.
Tests should be F.I.R.S.T. - fast, independent from each other, repeatable (e.g. independent from the network), self validating (either pass or fail, no manual steps in between), timely (written on time, not after production code is done).
9. Classes
If a test needs it, it’s fine to change a method from private to protected, if no other solution.
A class should be smaller than small. It should have only one responsibility.
Single Responsibility Principle (SRP) states that a class or module should have one, and only one, reason to change.
Responsibility = reason to change.
If you have problem with finding concise (unambigious) name for the class, it is likely it has too many responsibilities. Especially names including Manager, Processor, or Super.
Making things work and keeping code clean are two different activities that cannot be done simultaneously. So after you are done with the first, don’t forget the latter!
Don’t be afraid of having many small classes. The complexity comes from number of moving parts not number of classes. You will not change program complexity by dividing it into many classes, but you will increase the ease with which someone else can learn it, and find the piece that is relevant to them at the moment. It’s about organisingthe complexity.
Cohesion of a function is proportional to the number of instance variables it modifies. The number of instance variables of a class should be small and cohesion high. And now listen to that:
Often when you want to minimize number of function arguments and create small functions, the number of instance variables grow, and often also at the same time cohesion decreases. This is often the sign that another class tries to get out of the bigger class. Split them!
10. Systems
Separate system startup code from the rest of the code (initialization, etc.). Even avoid such lazy initialization (it introduces coupling):
public Service getService() {
if (service == null)
service = new MyServiceImpl(...);
return service;
}
Keeping modularity is more important than convenience! As a solution you can: move all initialization logic to main, use Abstract Factories, or use dependency injection (Spring).
Right separation of concerns - allows us to build systems incrementally, we don’t have to get it all right from the start. EJB1 and EJB2 is an example of bad separation of concerns (everything coupled to the container).
Aspects and proxies are an attempt used for separating cross cutting concerns, proxies have some drawbacks though (though Spring makes them transparent enough to be acceptable). Aspect like architecture enables it to be test-driven.
Always postpone architectural decisions to the last possible moment.
Don’t blindly follow emerging standards or hypes.
11. Emergence
Emergent design.
Rules of good design (by Kent Beck):
- Runs all tests (i.e. passes them)
- Contains no duplication
- Expresses the intent of the programmer
- Minimizes the number of classes and methods
12. Concurrency
Concurrency is a decoupling strategy: it helps us decouple what gets done from when it gets done.
Concurrency does not always improve performance.
Concurrency requires fundamental change in design strategy.
Correct concurrency is complex even for simple problems. Bugs are often not repeatable, therefore often incorrectly ignored.
Keep your concurrency code separate from other code.
Limit the places where a variable is accessed concurrently to minimum. Eventually you will forget to synchronize the access in one place.
If you can introduce immutable objects instead of synchronizing, do so. It’s worth the garbage collection overhead.
Try to partition your data in such a way that it can be used by independent threads.
Use java.util.concurrent.* collections instead of regular ones. In particular, you should use ConcurrentHashMap instead of HashMap always, as it is more performant in general.
Become familiar with java.util.concurrent.*, java.util.concurrent.atomic.*, java.util.concurrent.locks.*, e.g. ReentrantLock - can be acquired in one method and released in another, Semaphore - lock with a count, CountDownLatch - releases all threads after receiving a number of events.
Become familiar with concurrent execution models:
- producer-consumer - and a queue between, as a bound resource (limited capacity). They have to signal each other, and wait for the signal from another before doing anything.
- readers-writers - where readers read more often than writers write. Writers could wait for all readers to finish before they write, but they will starve in case of continuous readers. A balance needs to be found.
- dining philosophers - in other words processes competing for resources.
Most concurrency problems are combination of the three above. Learn the three above and their solutions.
Keep number of synchronized sections low, but also keep those sections as small as possible.
Writing correct shut-down is harder than you think. Plan enough time for that.
Testing concurrent code does not assure its correctness. But it can minimize its incorrectness. Write your tests very varied, with different parameters, try to cover extreme cases. Never ignore a situation when a test failed just once. Remember that the number of possibilities of concurrent execution of trivally simple code is huge. Chase every bug.
Make sure your code works outside of threads first.
Make your threaded code pluggable and tunable, so that you can test it independently.
Test your threaded code with more threads than processors. Things happen when the system switches betweent he tasks.
Test your code on different platforms (they have different task switching strategies).
Add random Object.wait(), Object.sleep(), Object.yield() and Object.priority() in your code, to increase possibility of failure. You can automate it by writting an utility class doing that, and then adding an aspect randomly enabling it or disabling at any method call. There is an example library doing that: https://www.research.ibm.com/haifa/projects/verification/contest/.
Avoid calling one locked section from another.
13. Successive Refinement
There is a long use case presented. To sum it up: code may be quite nice and clean initially, but once we add new functionality it can become a monster. Always refactor and clean up. But not before you have tests. Use TDD while refactoring.
Programmers who satisfy themselves with merely working code are behaving unprofessionally.
14. JUnit Internals
(Another use case)
15. Refactoring SerialDate
(Another use case)
16. Smells and Heuristics
(Set of numbered checks with explanations. I write only the new things.)
Comments
- inappriopriate information - when the information should rather be somewhere else(issue tracking system, source control)
- obsolete comment - outdated comment
- redundant comment - as it is clear from the code
- poorly written comment
- commented out code
General bad things
- multiple languages in one source file
- corner cases not handled (and tests missing)
- code at wrong level of abstraction (e.g.
pop(),push(), andpercentFull()in oneStackclass) - base classes depending on their derivatives
- too many functions in an interface
- feature envy - a function tries to read or modify variables of another class than its owner (though sometimes it may be neccessary)
- function with a boolean input (should be 2 functions instead)
- misplaced responsibility - code should be where the reader expects it to be, not where it is convenient for us at the moment
- inappropriate static - if we make a function static it means we do not expect that it is ever polymorphic; e.g.
HourlyPaidCalculator.calculatePay(employee, overtimeRate)is not really clean - use intermediate variables - because they can have descriptive names
- understand an algorithm before implementing it; don’t rely on try-error method; don’t assume that a function works because it passes all the tests if you don’t understand it; if you have problems understanding it - refactor it to become more obvious
- make logical dependencies physical (e.g. placing a constant in one place with a value that needs to match another value somewhere else is not a good idea)
- make temporal coupling visible
Java
- choose names appropriate to current level of abstraction (i.e. general enough to cover all cases), e.g.
connectionLocatorinstead ofphoneNumber - the length of a variable name should be proportional to the scope of the variable - for example loop counter is usually one character long and it’s better than a loger name
Tests
- use test coverage tool
- don’t skip trivial tests
- test corner cases
- test exhaustively around found bugs - they often hang out in groups :P
- keep your tests fast (so that you want to run them)
17. Appendix A: Concurrency II
(I’ll just write some selected stuff)
It’s a common misconception that increment operation ++ is atomic. Assigment is usually also not. Something like 8 steps can be involved in single assignment on the level of byte code, hence so many possible paths of execution in a multithreaded environment.
That’s why AtomicInteger, AtomicReference and AtomicBoolean are there since Java 5. They are not slower (because of special CAS feature of modern processors, which basically means that instead of locking, it just retries until it succeeds).
Nonthread-safe classes:
SimpleDateFormat- Database Connections
- Containers in
java.util.* - Servlets
Example of something not being thread safe even though each method separately is; assume that hasNext() and next() are both synchronized:
if (myThreadSafeIterator.hasNext()){
process(myThreadSafeIterator.next());
}
- between
hasNext()andnext()there is a break, and if this code is executed in >1 thread, the threads can interleave exactly here, and cause one thread to go beyond the iterator.
Solutions:
- wrap the whole code block into another
synchronized(myThreadSafeIterator)block (extract the call to “process” beyond it, to keep it as short as possible). This is client-based locking. Not very reliable solution (someone may forget to add this). - change the design of iterator, by merging both methods into one,
getNextOrNull(). This is server-side locking. Trivial isn’t it. If you cannot change the server side code, e.g. because it is a 3rd party library, add an adapter …or use another library :P
Book recommendation: Doug Lea “Concurrent Programming in Java: Design Principles and Patterns”.
18. Appendix B: org.jfree.date.SerialDate
(Just full source code for the SerialDate use case)
Comments
Comments: